
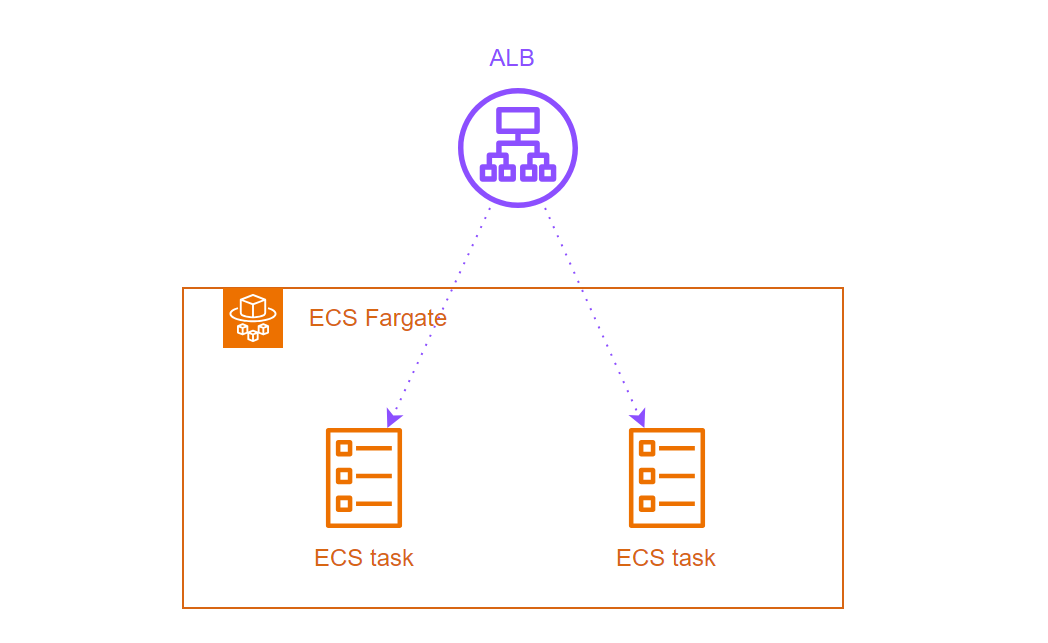
AWS構成図
AWS ECS(Fargate起動タイプ)で立ち上げたコンテナを、ロードバランサー(ALB)経由で通信させる構成。
エラー現象
AWSのECS Fargateでサービスの更新からデプロイしても、デプロイが失敗しタスクが更新されない現象が発生した。
ログを確認するとヘルスチェックに失敗したというログが出力されていた。
service ECS_SERVICE_NAME port 80 is unhealthy in target-group TARGET_GROUP_NAME due to (reason Health checks failed with these codes: [502]).
エラー原因
こちのAWSのブログによると、ELBからECSに対してヘルスチェックを行っており、コンテナへ接続できない、コンテナからの応答に時間がかかりすぎる場合に、異常判定されタスクが更新されないとのこと。
本アプリでは、コンテナ起動後にWEBアプリが起動するまで時間がかかっている可能性があるため、ここの設定を見直す必要がありそう。
解決方法
ECSにはhealthCheckGracePeriodSecondsというパラメータが定義されており、このパラメータに設定した秒数の間はヘルスチェックのステータスが無視される。その結果、ヘルスチェックのステータスが失敗となっても、コンテナの起動が異常判定されなくなる。
最大 2,147,483,647 秒まで設定可能。healthCheckGracePeriodSecondsに秒数を設定することで、ヘルスチェック失敗によるデプロイ失敗を回避できる。
(参考リンク)
Amazon ECS に ELB ヘルスチェックの猶予期間を追加
Amazon ECS サービス定義パラメータ
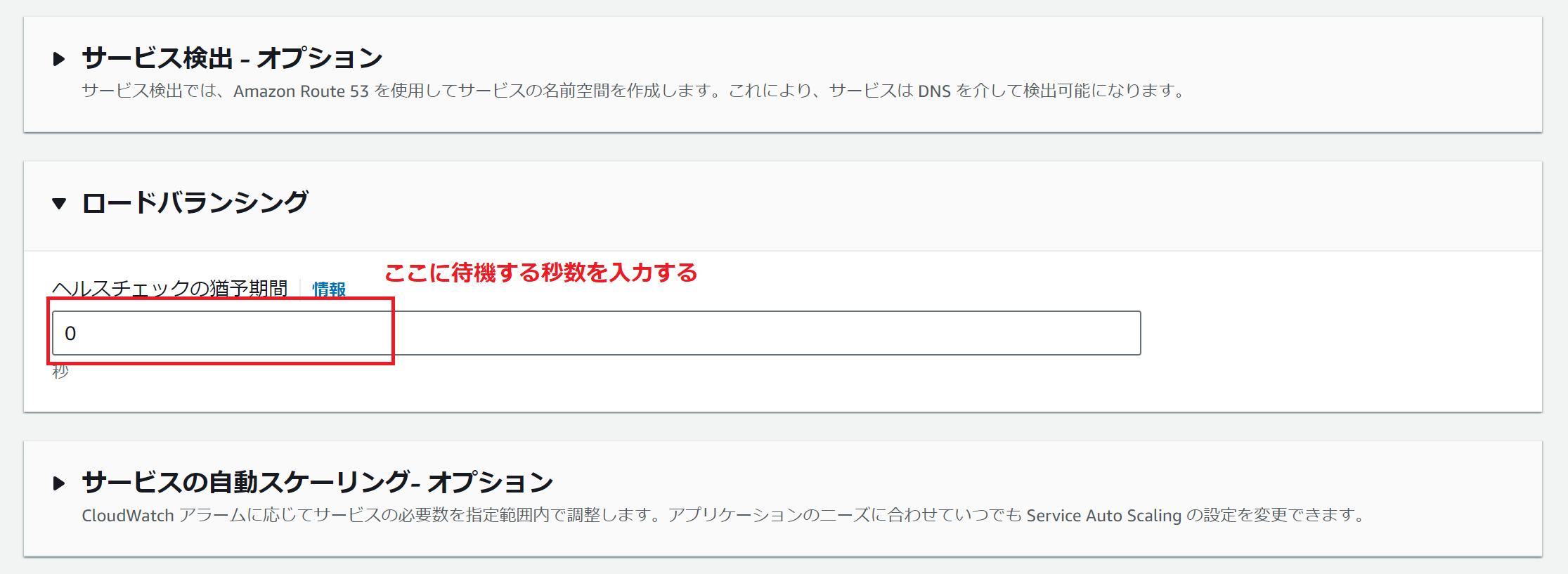
コンソールからサービス作成、更新
ロードバランシングの「ヘルスチェックの猶予期間」に待機する秒数を入力して、サービスを作成、更新する。
AWS CLIからサービス作成、更新
healthCheckGracePeriodSecondsパラメータを追加し、待機する秒数を設定する。
{
"serviceName": "my-service",
"taskDefinition": "my-task-def",
"loadBalancers": [
{
"targetGroupArn": "arn:aws:elasticloadbalancing:region:account-id:targetgroup/my-target-group/1234567890123456",
"containerName": "my-container",
"containerPort": 80
}
],
"desiredCount": 1,
"healthCheckGracePeriodSeconds": 300
}



コメント